Goal : How to extract Structured information (JSON) from Complex PDF document with Magic xpi
1/ Sign in on your adobe developer console (Adobe Developer Website)
Create a new project
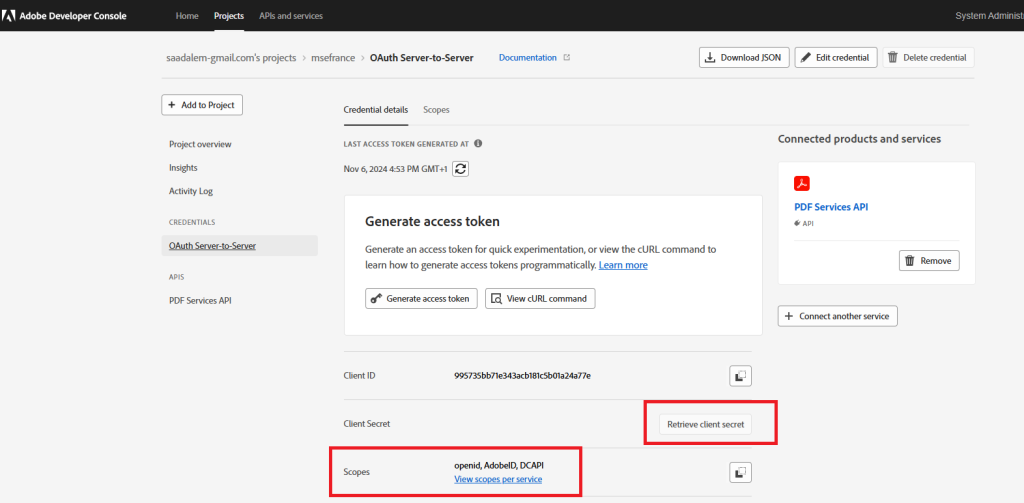
2/ Create an API Key
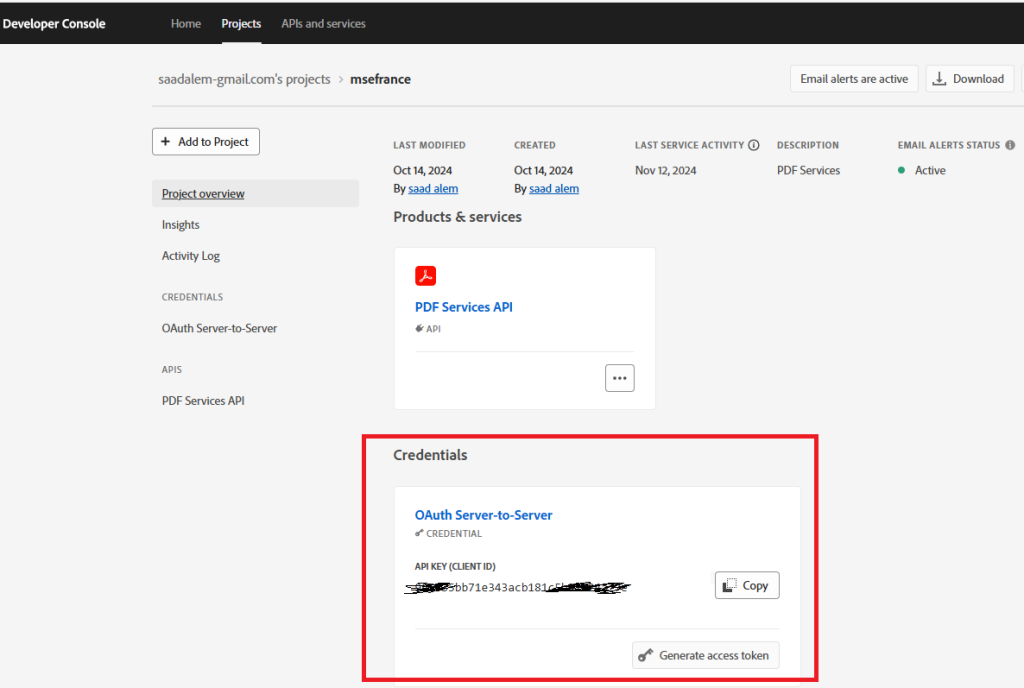
Copy your client id, client secret and Check the scope (openid, AdobeID, DCAPI)
3/ From now, you can use Postman to check the Adobe service API
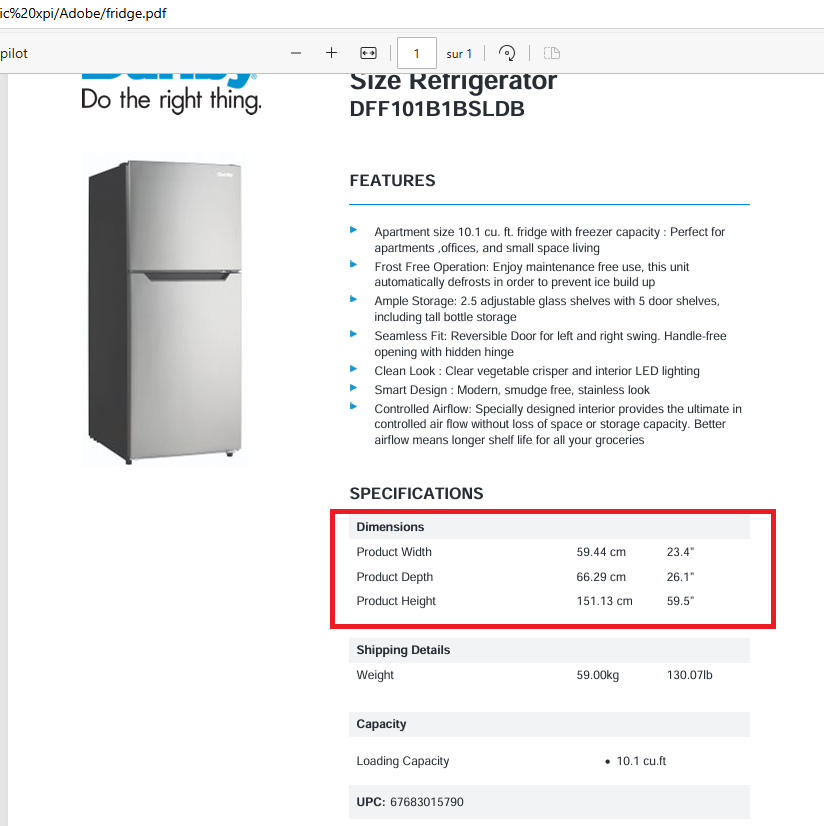
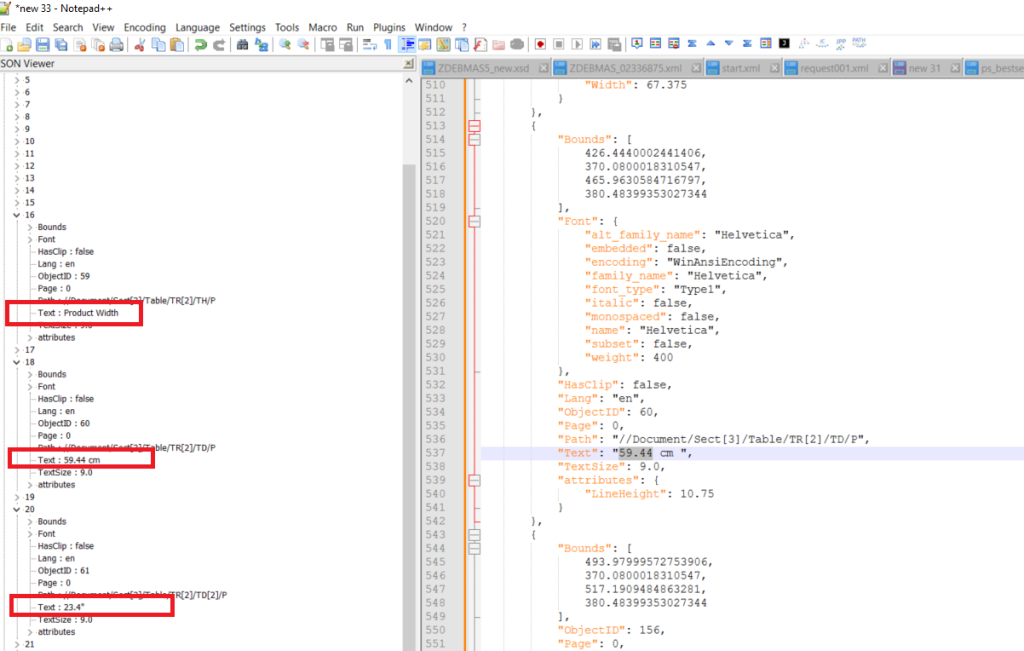
Assume that you want to retrieve the Dimensions of your product from the PDF document below
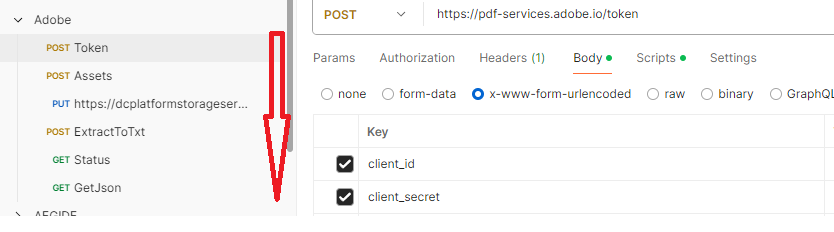
The sequence to retrieve the information is :
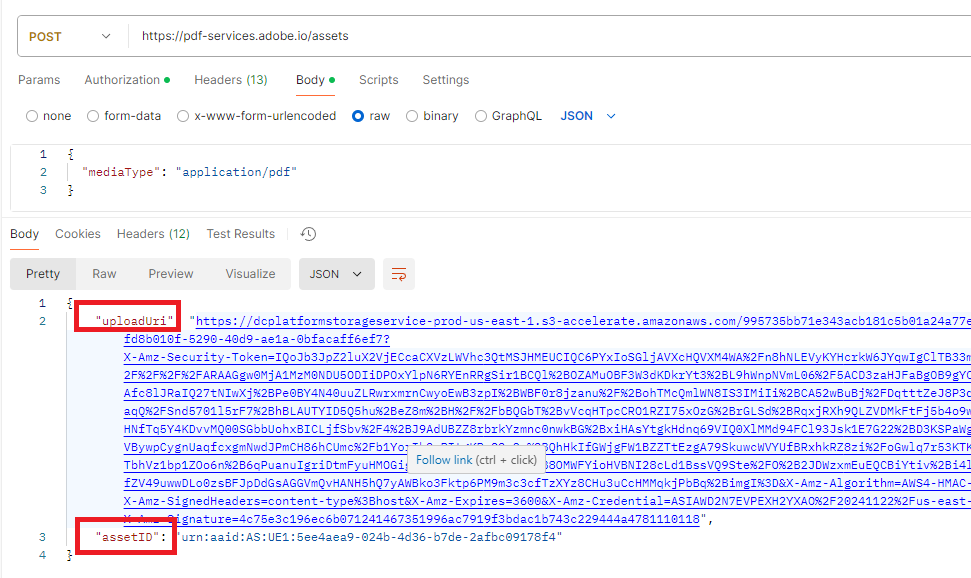
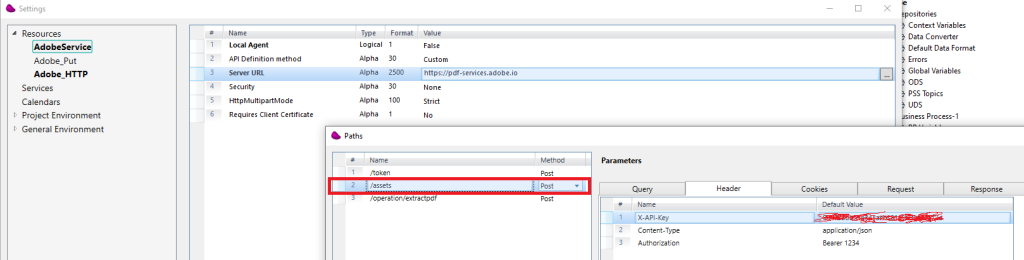
After getting the token, do a POST for an asset (https://pdf-services.adobe.io/assets) to retrieve an uploadUri and an assetid
Do a PUT on the uploadUri with your PDF file
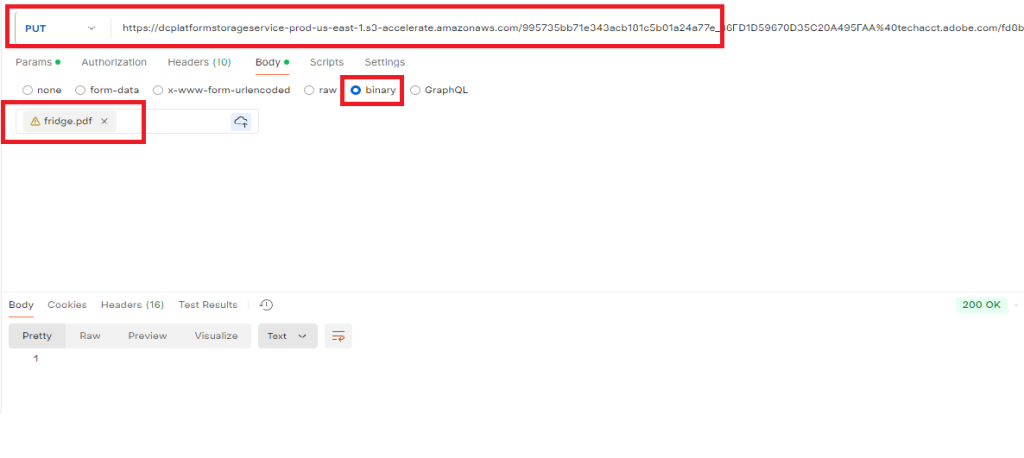
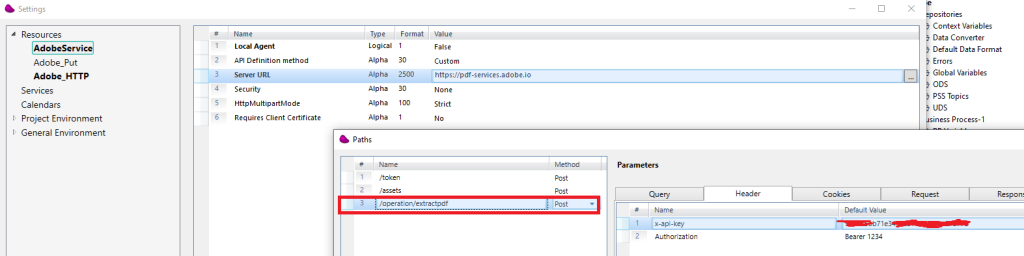
Do a POST on https://pdf-services-ue1.adobe.io/operation/extractpdf and pass the assetid
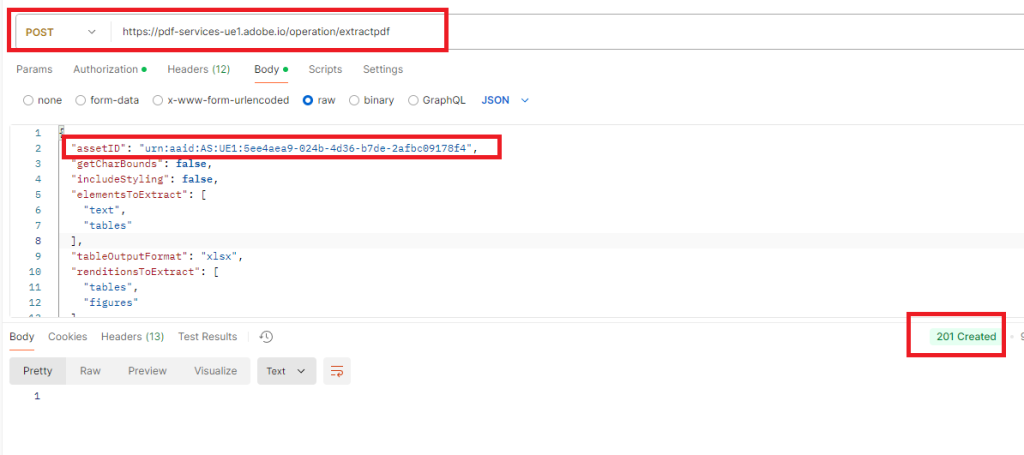
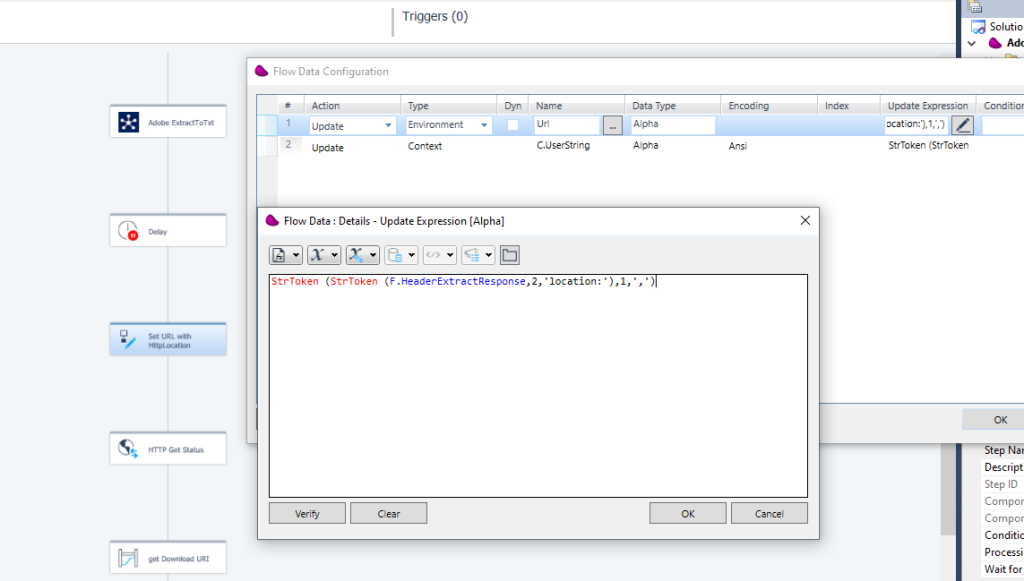
Retrieve in the response header the key : location
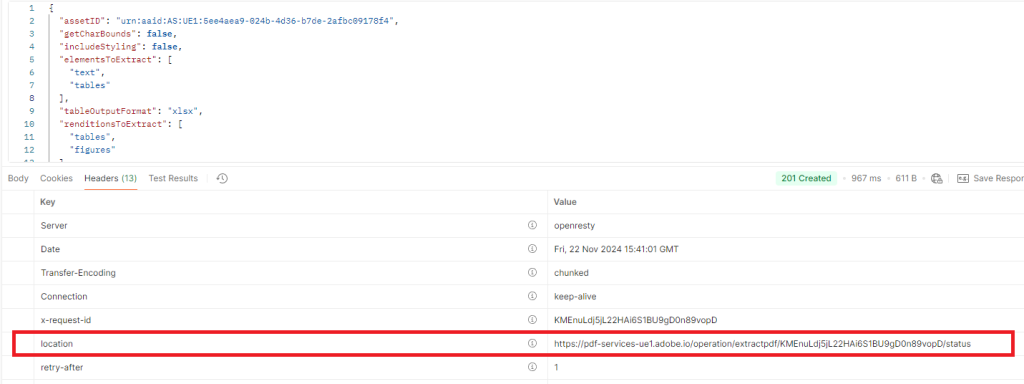
Do a GET the URL location to retrieve the download URI to get the json content
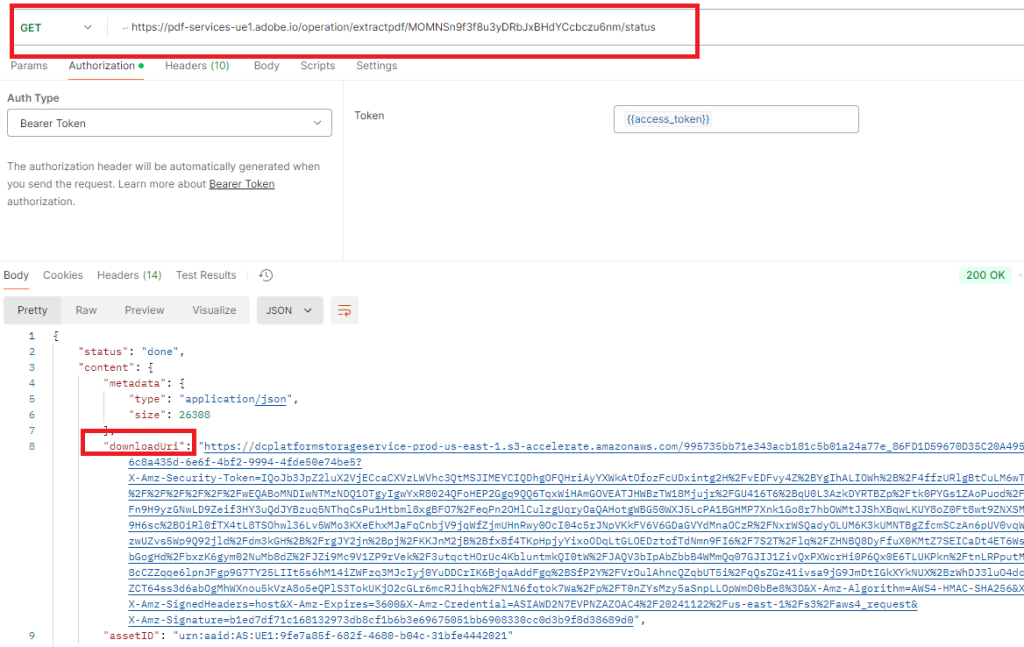
Do a GET on the downloadUri
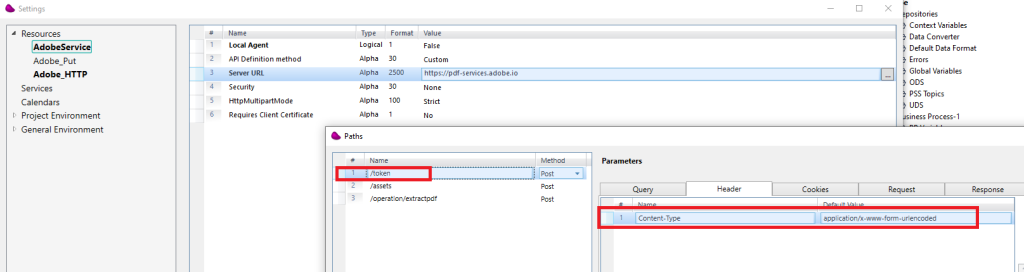
4/ Define Resources in the Magic xpi resources repository
0ne REST Client resource with 3 paths (token, assets, extractpdf) and one HTTP resource to do the PUT.
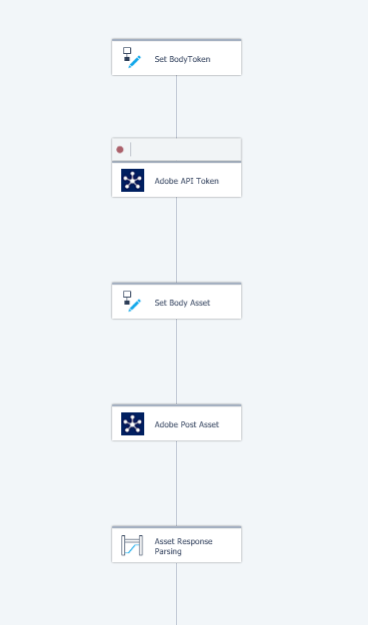
5/ Structure of the flow is like below :
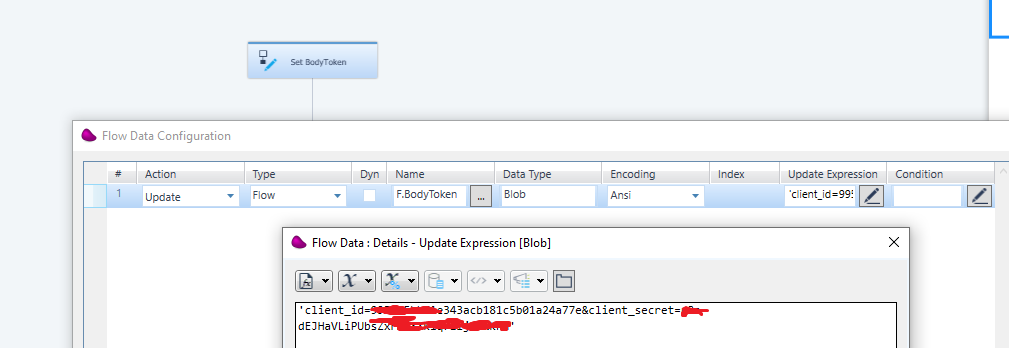
use the Set body token to step to update the http body
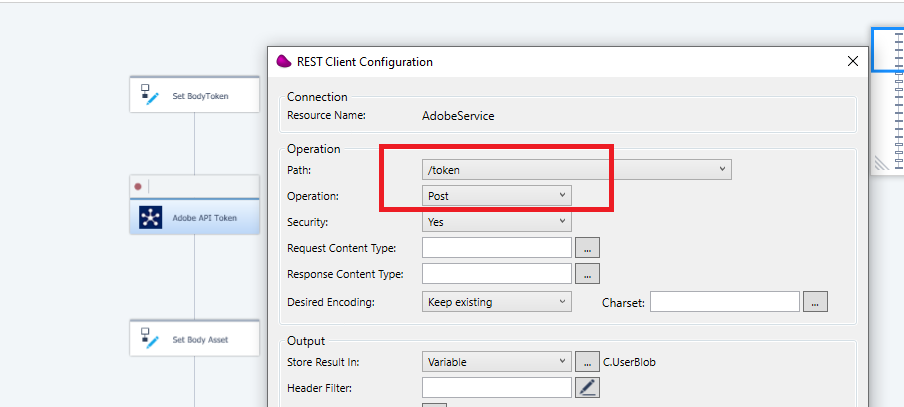
Drag and drop Rest client connector and call the token url by passing the body to DataBlob.
next, use Flow data connector to update 2 flow variables (F.accesstoken, F.BodyAsset)
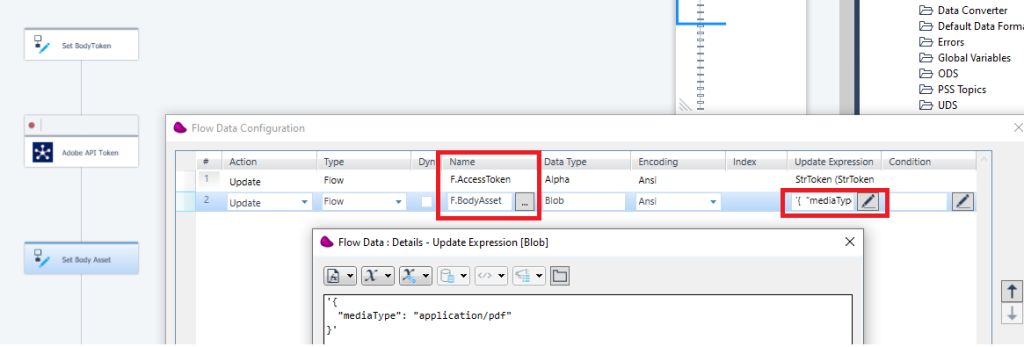
6/ Drag and drop Rest client to call assets
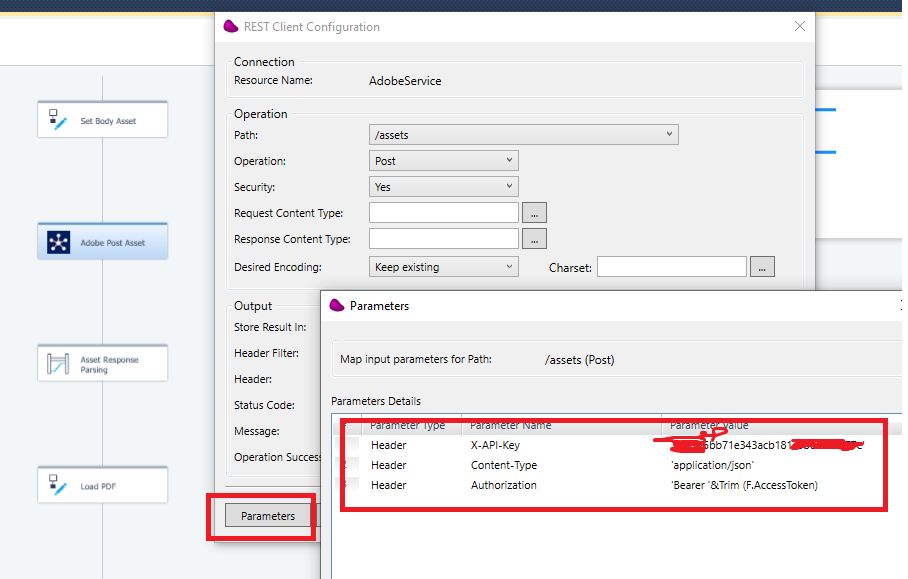
Click on Parameters to pass the API-Key and the Bearer token
In the mapping, pass the F.BodyAsset in the datablob
use the « Asset Response Parsing » step to get the « uploadUri » and the assetID

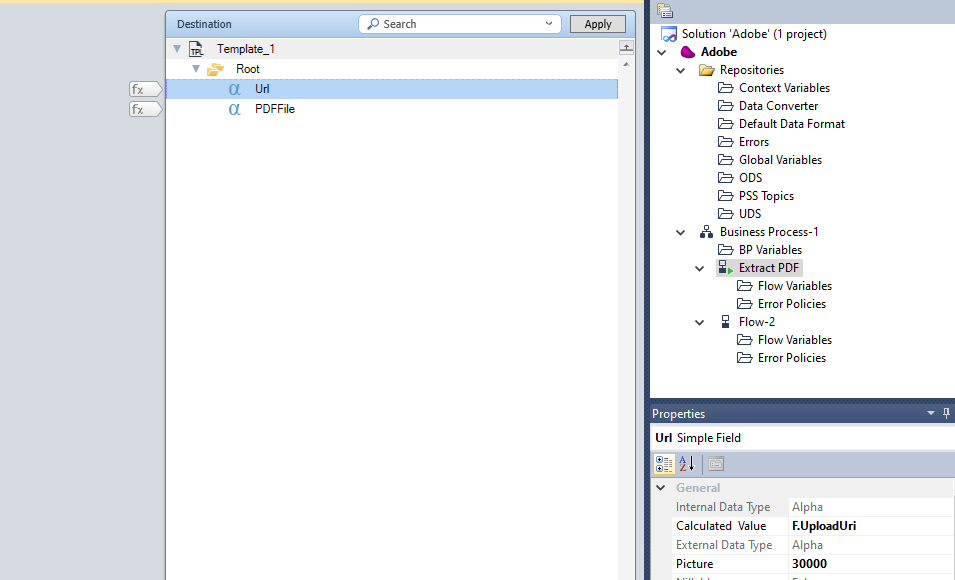
7/ To do the PUT, i’ll use powershell script with Magic xpi template
Define a template with 2 tags like below :
Invoke-WebRequest -Uri ‘<!$MG_Url>‘ -Method ‘Put’ -ContentType ‘application/pdf’ -InFile ‘<!$MG_PDFFile>‘ > ‘c:/tmp/trace.txt’
use Datamapper to merge values on the 2 tags
after this step, you must obtain a powershell script (uploadPDFAdobe.ps1)
Then execute the powershell script with a file management and run command line
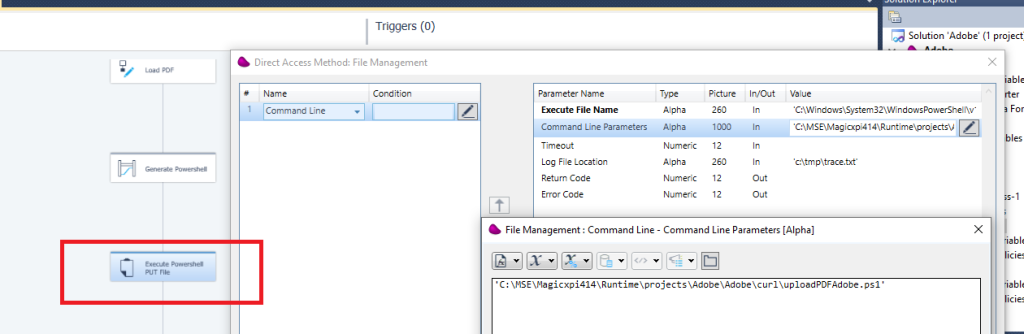
8/ After executing this step, your PDF file is uploaded to Adobe Service cloud platform
9/ Extractpdf method
Drag and drop Flow data component and update a flow variable to update the body (F.BodyExtract)
Populate the AssetID (step 6)
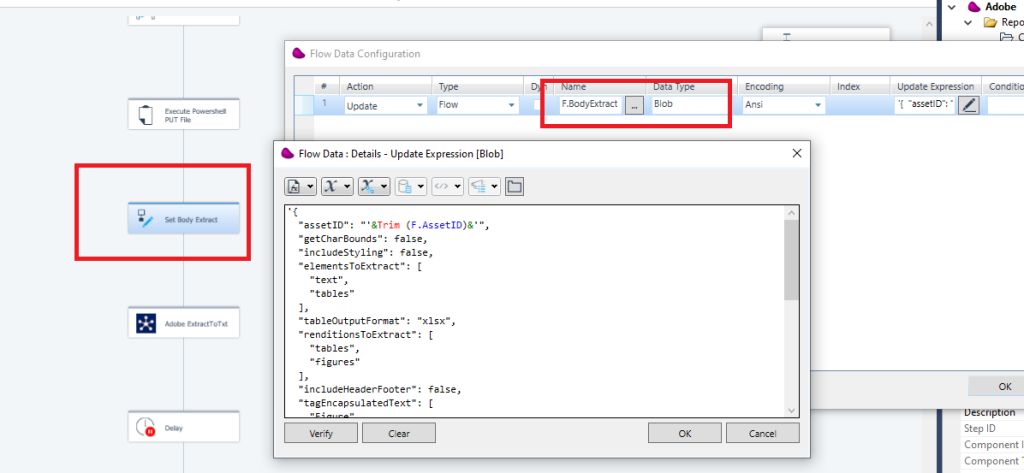
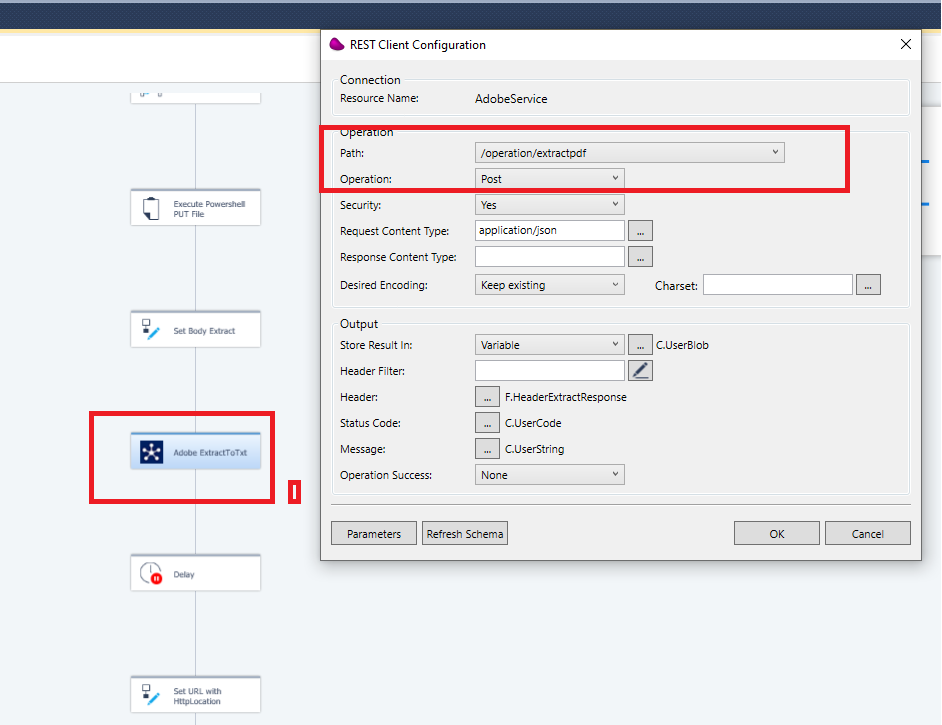
use REST Client connector to call the the extractpdf method
9/ Set a delay of 5 secs.
10/ Retrieve the status of the result
This url is retrieved from the response header
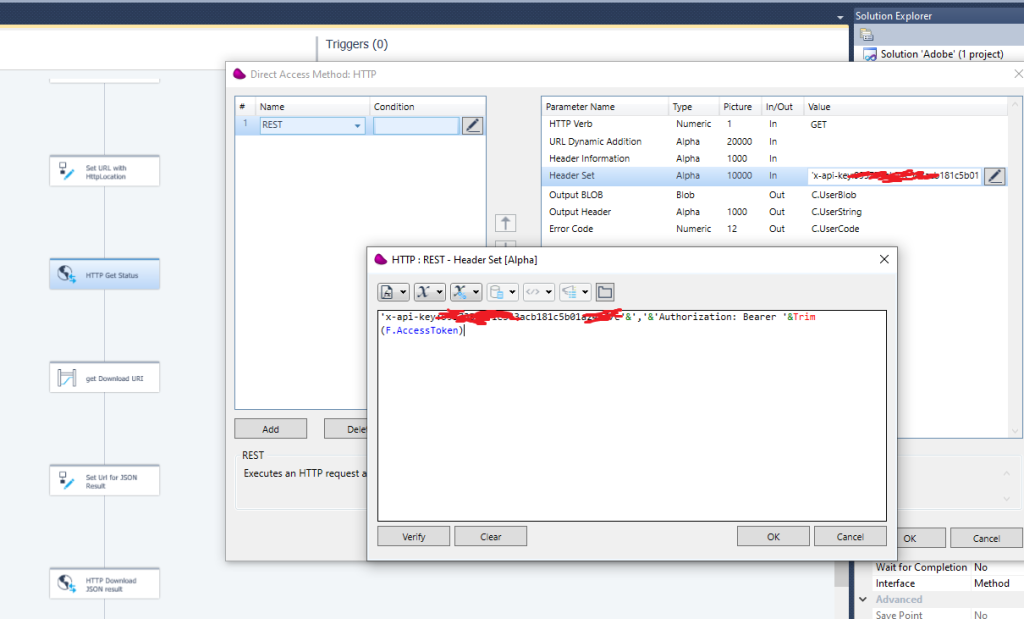
Drag and drop HTTP connector to call the status method
Next, use the datamapper to parse the json response
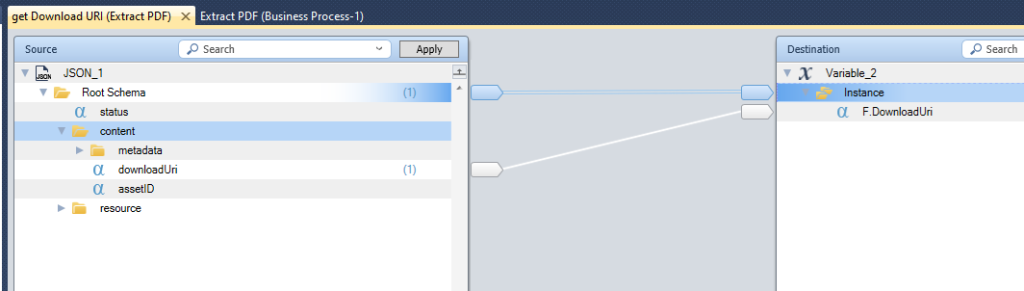
11/ use the HTTP connector to download the JSON result
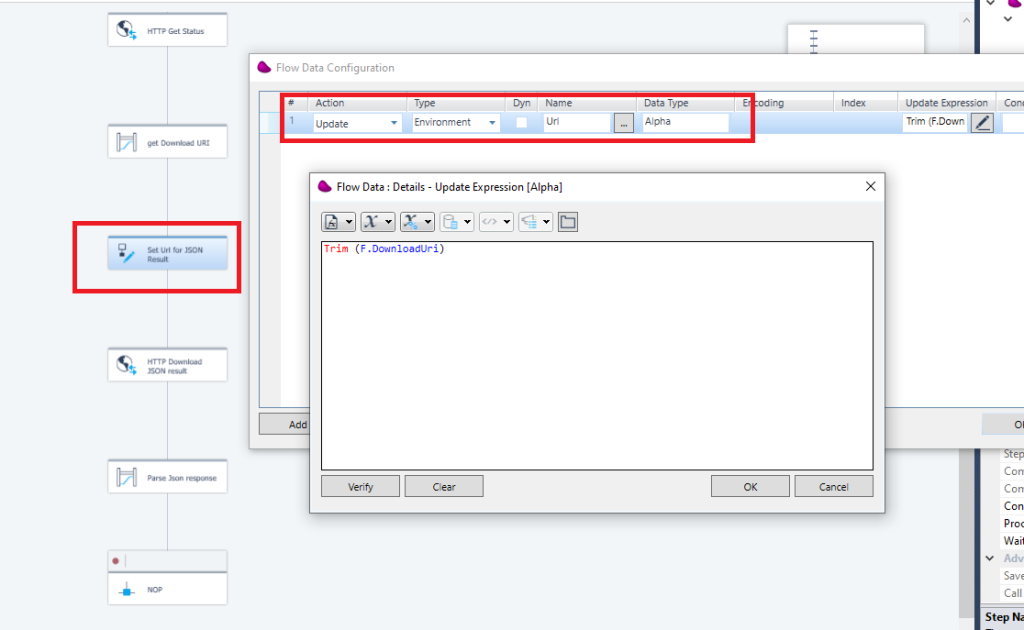
Update the environment variable with the DonwloadURI
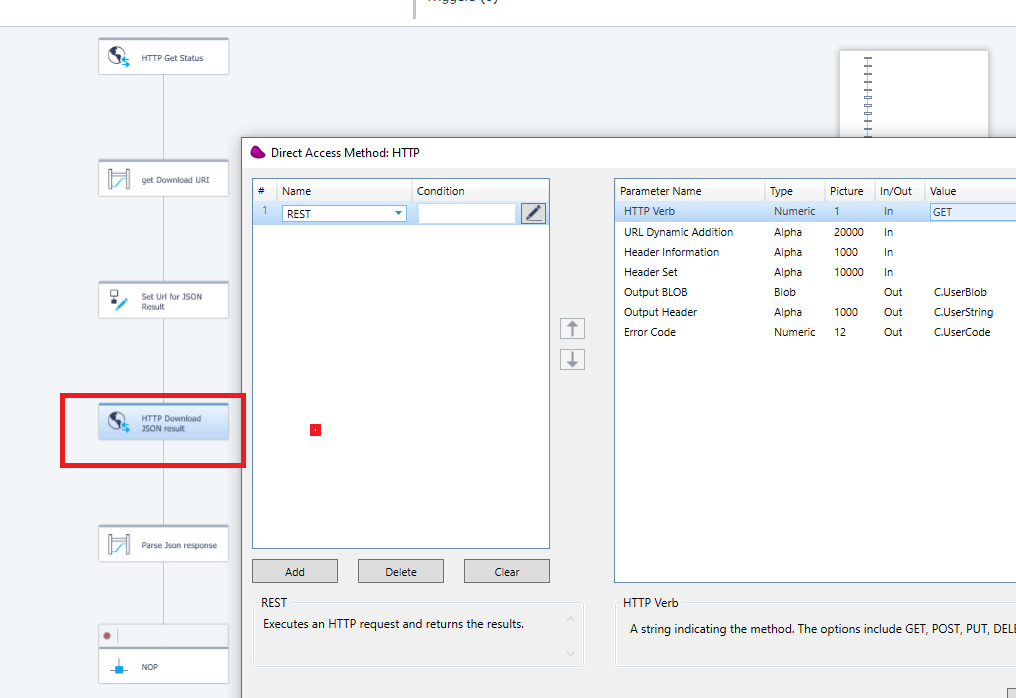
use the datamapper to extract information from the PDF file using JSON schema
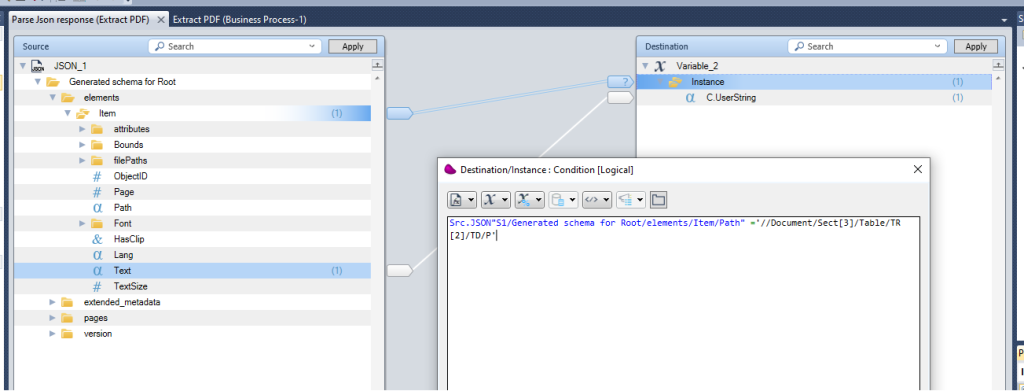
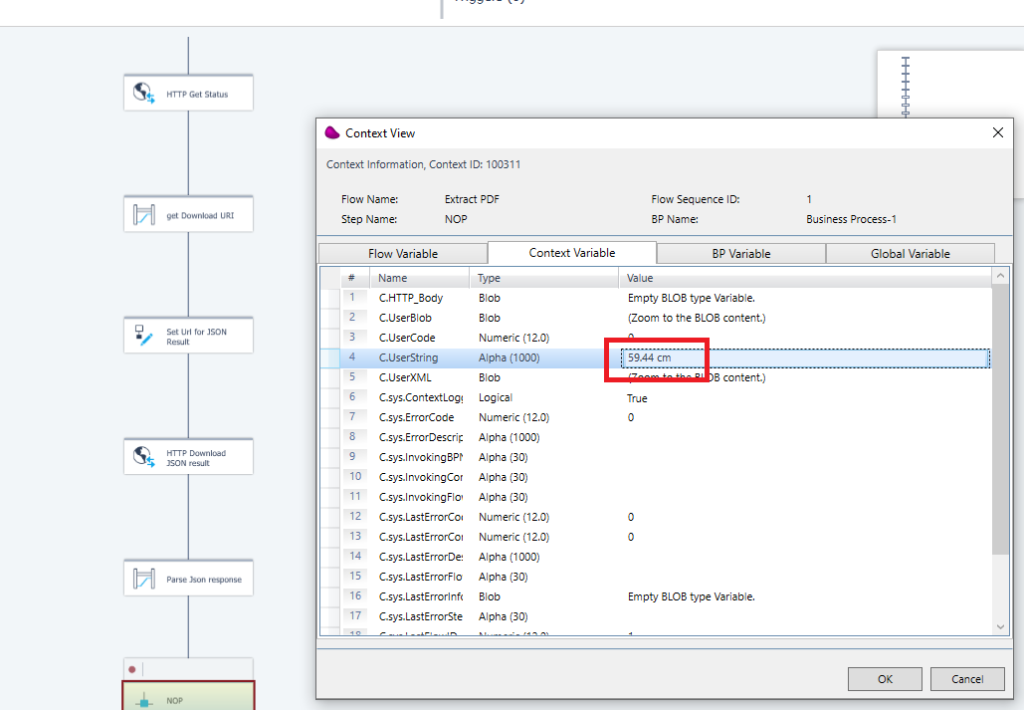
use a Condition on the destination node to retrieve the « Product Width »